Distributed Tracing on Hybrid Cloud using Apache Kafka
The title sounds cool, right? I know, but what is this distributed tracing? I had the same question when I was asked to set one up for a client.
Let’s get some background
Distributed tracing is a method used to debug, monitor, and troubleshoot applications built using modern distributed software architectures. The applications should be instrumented with the OpenTracing APIs* to identify an incoming request to pinpoint where failures occur and what causes poor performance.
Jaeger is an OpenSource distributed tracing technology graduate by Cloud Native Computing Foundation (CNCF) used to monitor and troubleshoot microservice-based distributed systems for performance optimization, root cause analysis, service dependency analysis, and many more use cases. It comprises five components:
- Client: A language-specific OpenTracing API that is implemented by instrumenting the applications
- Agent: a network daemon that listens for spans** and sends it over to collectors
- Collector: Validates, indexes and stores the traces received from the agents
- Ingester: An integrated service between the Kafka topic and storage backend
- Query: a service to retrieve the traces*** from a storage backend and hosts a UI to display them
* The OpenTracing API provides a standard, vendor-neutral framework for instrumentation. A developer can introduce a different distributed tracing system by simply changing the configuration of the Tracer in the code.
** Span represents a single unit of work that includes the operation name, start time, and duration
*** A trace is made up of one or more spans
What’s in the Cloud today?
Now that we learned some Jaeger jargon let’s talk about this specific use case at play. The client I worked with had set up the entire Jaeger stack on Amazon Web Services (AWS) as follows:
- Applications are instrumented with the Jaeger Clients (AWS Lambda Functions) to interact directly with the Jaeger collector to forward the spans
- The Jaeger collector is deployed on an EC2 instance and configured with an AWS Managed Streaming for Apache Kafka (MSK) to validate, index and store the spans
- The Jaeger Ingester was set up on an EC2 instance to read the spans from AWS Kafka and write it to the Elastic Search to view them on the Jaeger UI
The Requirement
It seems like everything is in place, right? No! Here comes the tricky part; the client has planned to implement distributed tracing (Jaeger) for the mission-critical applications running on an On-Prem OpenShift cluster for analytics, visualization, and reporting.
Given the requirements, the initial plan was to send the traces directly from agents (on OpenShift cluster) to the collector (on AWS).
Sounded pretty straight forward at first glance, but a wrench was thrown in as I realized the data transfer between On-Prem applications and AWS has to be secure. I also found that there wasn’t enough bandwidth to send real-time span data from the Jaeger agent (on OpenShift cluster) to the Jaeger collector (on AWS). If the spans are backed up, the agents will drop the spans and the whole purpose will be defeated. Even though Jaeger supports gRPC TLS communication between the agent and the collector, bandwidth was a primary concern.
Whiteboard Session
With the bandwidth and security in transit issues, I had to go back to the drawing board and come up with a solution to address these two significant areas:
- On-Prem Data retention in case of connectivity issues or data queuing due to bandwidth limitations
- Network bandwidth limitation between On-Prem Openshift Cluster and AWS
After hours of brainstorming, I came up with the following: well, to start off with,
- Ensure the version compatibility between Jaeger, Kafka, and MirrorMaker
- Install Jaeger components (only collector & agent) using it’s OpenShift Operator
- Leverage the self-provision option in the Jaeger OpenShift Operator to auto-install the Kafka cluster(ZooKeeper, Kafka and MirrorMaker) by using a Strimzi Kafka Kubernetes Operator
- Use MirrorMaker Kubernetes object provided by Strimizi Kafka Kubernetes Operator to replicate the OpenShift Kafka cluster events to the AWS MSK cluster
Note: It’s worth noting that the Jaeger collector or agent is not designed to handle the load when backed up by the spans, but a Kafka cluster can be used as a streaming service between the Jaeger collector and backend storage (DB) to offload the span data.
Note: To leverage the self-provisioning Kafka cluster option in Jaeger, a Strimiz Operator must be deployed in the OpenShift cluster before the Jaeger Openshift Operator deployment.
R & D
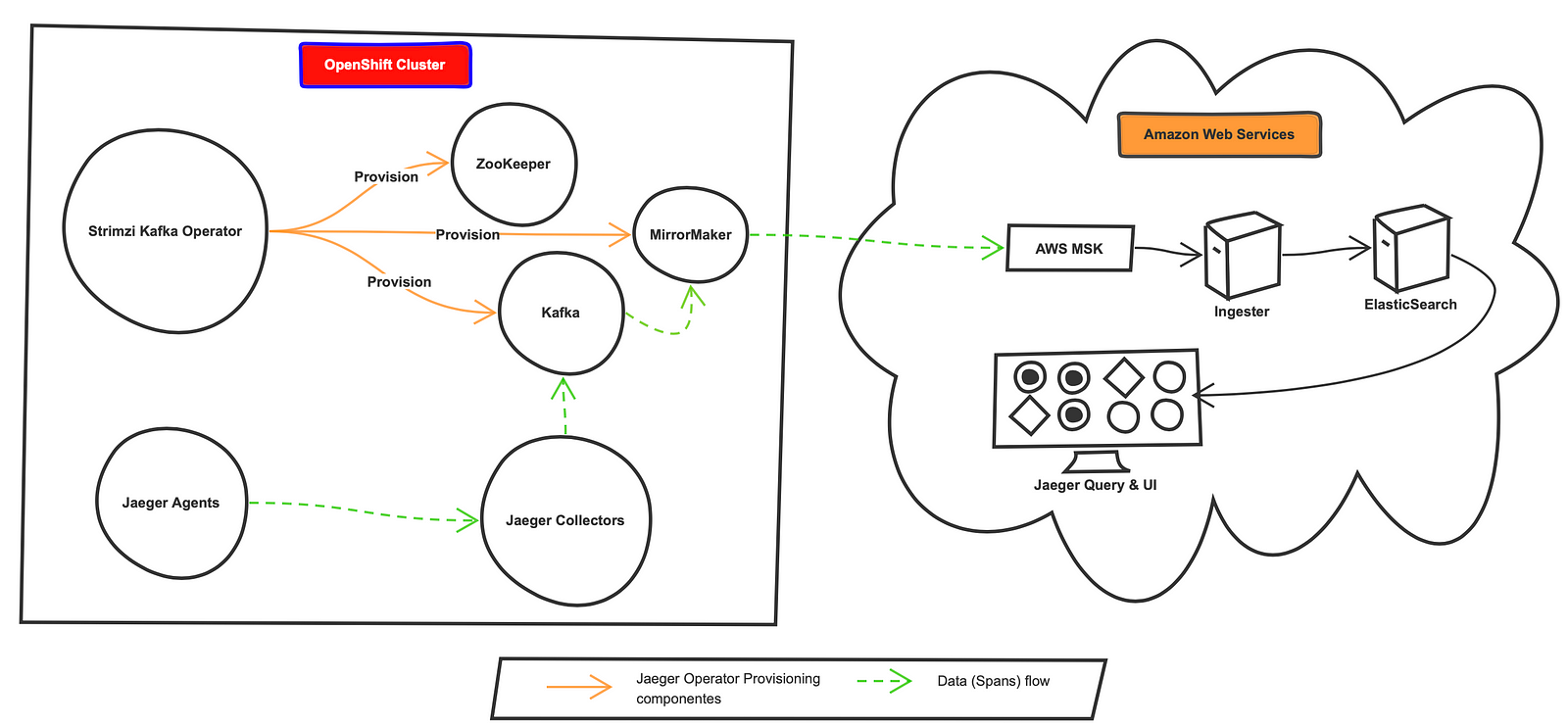
To prove the findings in the whiteboard session (Figure 2), I started with our in-house OpenShift cluster and an AWS MSK cluster to test the use case and understand the nuances in the process,
Trial & Error
When the Jaeger Openshift Operator is deployed with a self-provision Kafka cluster, it deployed the following:
- Four components of Jaeger (agent, collector, ingester, and query)
- A Kafka Cluster using Strimizi Operator
- Backend storage (ElasticSearch)
As per the design (Figure 2), I only needed the Jaeger agent, collector and a Kafka cluster, but I realized that there is no option in Jaeger Openshift Operator to enable or disable the backend storage such as Cassandra or ElasticSearch, ingester, or the query components (Figure 3).
Alteration
To overcome the above challenge, instead of using the Jaeger OpenShift Operator, I created the required Jaeger components (collector and agent) as raw Kubernetes YAML files:
- Collector has the Kubernetes Deployment, ConfigMap, and a Service YAML files
- The agent has the Kubernetes Daemonset as it needs to run on every node in the OpenShift cluster and a Service YAML files
For the Kafka cluster, I used the Strimizi Kafka Kubernetes Operator to deploy a simple Kafka cluster and a Kafka topic.
Before deploying the Jaeger’s agent and collector to the OpenShift cluster using the raw Kubernetes YAML files, I set the backend storage type to Kafka with the Kafka Brokers and Kafka topic information in the Jaeger collector’s Kubernetes Deployment YAML file.
Hello World Spans
Now that the architecture is altered (Figure 4), I wanted to make sure that Jaeger collector can forward the spans to the Kafka cluster. I created and deployed a sample Python application instrumented with the Jaeger client libraries to the OpenShift cluster.
On the Jaeger side of the house, the agent was able to listen and batch the spans, the collector was receiving the spans from the agent. On the Kafka side of the house, the spans were actively streamed into the Kafka topic.
At this point, I confirmed that Jaeger successfully communicated and forward the spans to the Kafka.
Replication
Now to replicate the spans from the OpenShift Kafka topic to AWS MSK’s topic, I used the Strimizi Kafka Kubernetes Operator’s MirrorMaker. MirrorMaker is one of Kafka’s features used to replicate the events between multiple Kafka instances.
I configured the MirrorMaker Kubernetes YAML file with the consumer (OpenShift Kafka) and producer (AWS MSK) clusters information and deployed it to the OpenShift cluster (Figure 5).
VOILA, It worked! I was able to read the sample Python application’s spans in the AWS’s MSK topics events.
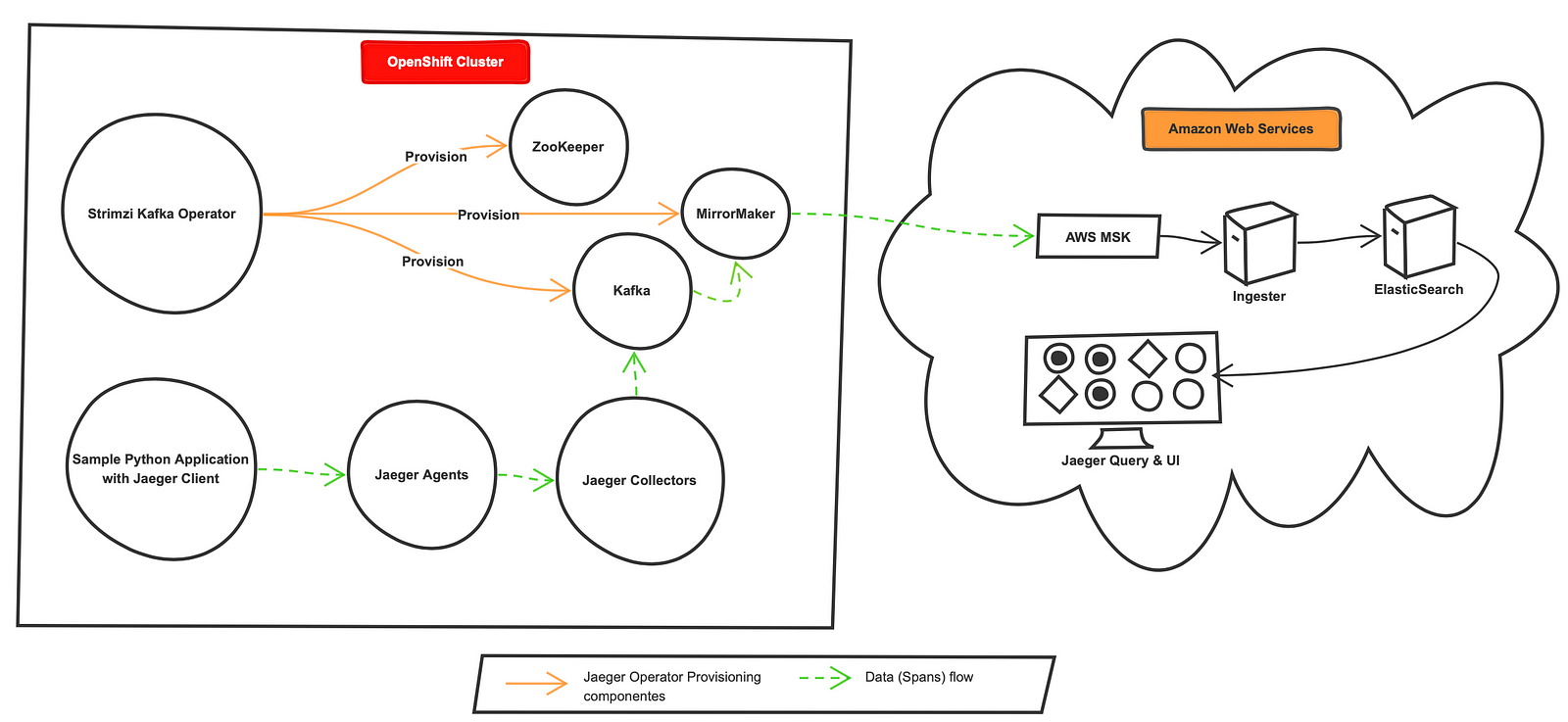
The Ultimate Sketch
Following the alterations through the trial and error phase, here is the final design
The End
To rephrase my journey, I started with the Jaeger OpenShift and Strimzi Kafka Kubernetes Operators. Still, after the R&D and alterations to the initial sketch, I wind up with raw Kubernetes YAML files for Jaeger components and Strimzi Kafka Kubernetes Operators for Kafka cluster.
With the ultimate sketch, I wrap up the distributed tracing in a hybrid cloud using Apache Kafka blog without compromising the On-Prem Data retention and Network bandwidth limitation concerns.
I’m always up for a discussion; leave a comment below!!
Well, that’s it for now. See you again!
Happy Tracing 🚀🚀

{kind=link}
{kind=link}